
Author: Clare Stone
The demanding regulatory environment increasingly places challenging stipulations around the number of model runs required, and the timeframe in which results are to be produced. Combined with the ever-increasing volume of data that most insurers wish to process this can drive the need for a scalable model solution.
In this article, we will look at some of the techniques to successfully scale your models.
Which Scaling Options are Available?
There are different scaling options available for users of Mo.net and we will consider each of these and the considerations in each case.
Multi-threading: This splits the calculations for a single projection task across multiple threads running the same process on a single machine. Each thread runs on an available core of the hardware that you are processing the job on. This method of scaling is possible even with the lowest level of licence but you are limited to the number of cores on the hardware you are using to run the projection for scaling.
Master/ Worker: This splits the calculations for a single projection task across the available cores on a single or multiple machines. The master manages the work allocation, as well as coordinating and distributing work to the worker community. The master can itself be used as a worker. This requires a professional or higher licence type plus worker licences, but you can scale up as much as you like to reduce your run times.
High Performance Computing (HPC): This splits the calculations for a single projection task across HPC Compute Nodes. For this an on-premise or Azure HPC environment needs to have been pre-configured requiring internal knowledge/expertise around HPC. You also need an enterprise licence.
Choosing the best option for you depends on your scaling needs. If you only need to scale the model on a small scale to reduce your run times by up to 50%, then multi-threading will meet your needs. However, a requirement to reduce run times by up to 90%, or increase throughput in order to carry out an increased volume of scenarios, would require the use of master/worker or HPC for scaling.
Coding Considerations
When coding your model if you want to scale it you need to make sure that the code is thread-safe. This mainly involves considering code which would not be carried out for every record that is processed, and is likely to relate to code directly in the individual or group projection task itself.
An example is writing code to create an output folder for the results which you would only want to create once, and therefore you need to ensure this is carried out only by the master thread.
When running a group projection task using the RunManager class to run multiple scenarios there are two options for how the work is split.
- The scenarios themselves can be split across the threads/workers
- The inputs table can be split across the threads/workers for each scenario
The default behaviour is for the scenarios to be split, as it is assumed that each scenario would take a similar amount of time to process. This would therefore enable optimal processing time to be more easily achieved this way, provided the number of scenarios to process can be fairly evenly split across the number threads or workers that are being used. If you wish to split the inputs table across the threads/workers then code needs to be added to the group projection to effect this split.
Setting the Splits
Whether splitting by scenarios or inputs table you need to determine how many blocks to split across.
When running multi-threaded you need to consider how many cores you have available to you on the machine being used to process the run.
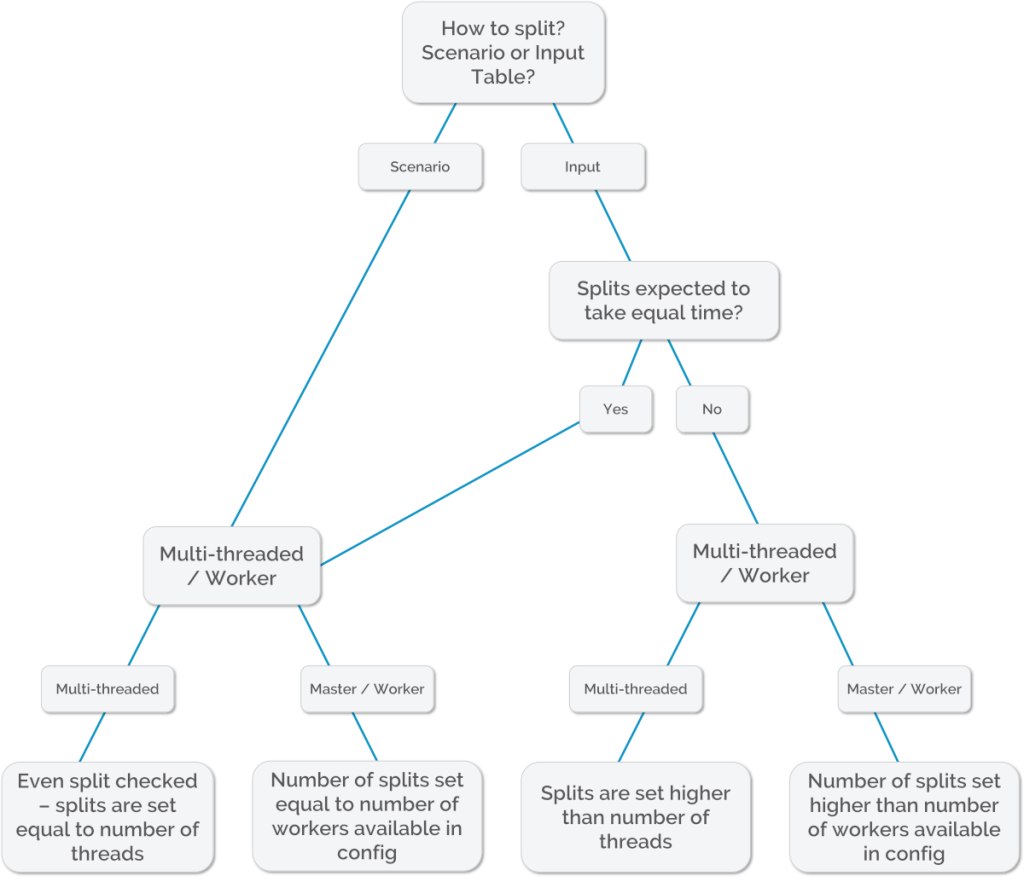
If the splits are expected to take a fairly equal amount of processing time…
Then the general best practice principle would be to set the splits equal to the number of threads. This can be done automatically by checking the Even Split checkbox. Set the number of threads according to the cores available on the machine, allowing for the fact that other applications running may also be using one or more cores.
If the splits are not expected to take a fairly equal amount of processing time…
Then leave the Even Split checkbox unchecked, and set the number of splits to be higher than the number of threads. Finding the optimal number of splits for a particular input file may be an iterative process.
When running using workers…
You need to be aware of how many cores (workers) you have available to you in the worker configuration that will be used for running the task. The number of splits would normally be set equal to the number of cores available, but you can choose to create a higher number of splits such that each worker would process multiple splits. This would be the preferred approach if the split data is expected to take different amounts of time to process.
Memory Considerations
The Mo.net master sends the model, assumptions and packets of input data to the worker service across the network, without the need for a network file share. This means that results are held in memory whilst the run is processed and then passed back to the master. Ordinarily this should not cause problems and should in fact mean that the packets of input data are processed faster because there is no writing of intermediate output, but there are options for reducing memory usage and writing intermediate worker results out if necessary. This obviously comes with additional considerations around network storage space and may slow down the running of your model.
I hope this article offers some guidance to those interested in the various approaches to scaling their models. If you have any questions or need assistance with an upcoming project, please don’t hesitate to reach out to us.
Comments are closed.